
Python之Numpy库学习(2)
ndarry的索引切片与迭代
- 索引: ndarry数组的索引和python列表的索引相同, 都是用[index]表示.
- 切片: 通过对每个以逗号分隔的维度执行单独的切片, 你可以对多维数组进行切片.
因此, 对于2D数组,我们的第一片定义了行的切片, 第二片定义了列的切片.
注意, 只需输入数字就可以指定行或列. 上面的第一个示例从数组中选择第0列.
下面的图表说明了给定的示例切片是如何进行工作的:
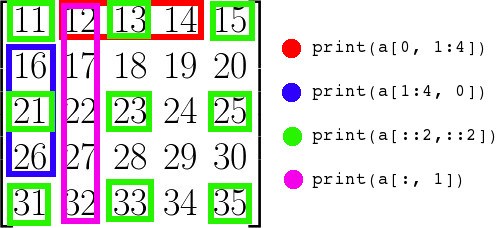
而迭代多维数组是相对于第一个轴完成的, 如果想要对数组中的每个元素执行操作, 可以使用 flat 属性, 该属性是数组中所有元素的迭代器:
1 | import numpy as np |
ndarry的形状和维度变换
ndarry的形状和维度变换有以下这些常用函数:
| 函数 | 说明 |
|---|---|
| ndarry.reshape(shape) | 不改变原ndarry元素并返回一个内容一样的shape形状的ndarry |
| ndarry.resize(shape) | 改变原ndarry元素并使其与shape形状相同, 无返回值 |
| ndarry.swapaxes(ax1, ax2) | 返回ndarry的n个维度中的两个维度调换后的ndarry且不改变原ndarry |
| ndarry.flatten() | 返回一个原ndarry降一维的ndarry |
| ndarry.astype(type) | 返回一个新的数据类型为type的ndarry |
| ndarry.tolist() | 返回ndarry转换而成的的列表 |
例如:
1 | import numpy as np |
还可以将不同数组叠加在一起, 或者将一个数组拆分:
| 函数 | 说明 |
|---|---|
| np.stack(arrays, axis=0) | 沿在aixs轴将n个形状完全相同的数组合并 |
| np.vstack(tup) | 在竖轴将n个不同数组堆叠, tup为一系列横轴数目相同的数组 |
| np.hstack(tup) | 在横轴将n个不同数组堆叠, tup为一系列竖轴数目相同的数组 |
| np.dstack(tup) | 在Z轴将n个不同数组堆叠, tup为一系列Z轴数目相同的数组 |
| np.r_[] | 沿横轴轴叠加数字创建数组 |
| np.c_[] | 沿竖轴叠加数字创建数组 |
| np.split(a, indices_or_sections, axis=0) | 在数组a的axis轴上拆分数组, 可以指定要返回的均匀划分的数组数量, 或指定要在其后进行划分的列 |
| np.vsplit(a, indices_or_sections) | vsplit与axis=0时的split相同 |
| np.hsplit(a, indices_or_sections) | hsplit与axis=1时的split相同 |
| np.dsplit(a, indices_or_sections) | dsplit与axis=2时的split相同 |
合并:
1 | import numpy as np |
需要注意, 使用stack的时候, 数组之间shape必须完全相同, vstack要求横轴(0轴)元素数目相同, hstack要竖轴(1轴)元素数目相同, dstack要求深度元素数目相同, 此时才能合并, 不然无法合并.
拆分:
1 | import numpy as np |
通过例子可以看出, 当axis=0时, 划分的数组横轴(0轴)数目相同, 当axis=1时, 划分的数组竖轴(1轴)数目相同. 当指定其后拆分的行或列时, 会按照类似于切片的拆分, 如例子中的np.split(a, (1, 2), axis=1), 类似于将列像[:1], [1:2], [2:]这样切片.
ndarry与标量之间的计算
ndarry与标量之间的计算有以下这些常用函数:
| 函数 | 说明 |
|---|---|
| ndarry.mean() | 返回ndarry所有元素的平均值 |
| np.fabs(x) | 对 ndarry x的所有元素取绝对值, 不改变原ndarry的值 |
| np.sqrt(x) | 对 ndarry x的所有元素取平方根, 不改变原ndarry的值 |
| np.square(x) | 对 ndarry x的所有元素取平方, 不改变原ndarry的值 |
| np.log(x) | 对 ndarry x的所有元素取对数, 不改变原ndarry的值 |
| np.ceil(x) | 对 ndarry x的所有元素取ceiling值, 不改变原ndarry的值 |
| np.floor(x) | 对 ndarry x的所有元素取floor值, 不改变原ndarry的值 |
| np.rint(x) | 对 ndarry x的所有元素进行四舍五入, 不改变原ndarry的值 |
| np.modf(x) | 将 ndarry x的所有元素的整数部分和小数部分以两个独立数组的形式返回 |
| np.sin(x) | 对 ndarry x的所有元素取sin值, 不改变原ndarry的值 |
| np.exp(x) | 对 ndarry x的所有元素取指数值, 不改变原ndarry的值 |
| np.sign(x) | 对 ndarry x的所有元素取符号值1(+), 0(0), -1(-) 不改变原ndarry的值 |
例如:
1 | import numpy as np |
ndarry之间的比较
ndarry之间可以使用 < > <= >= == != 进行比较, 此时返回ndarry数组, 类型为bool
除此之外还有以下方法可以对ndarry之间进行比较:
| 函数 | 说明 |
|---|---|
| np.maximum(x, y) np.fmax(x, y) | ndarry对位元素最大值的计算 |
| np.minimum(x, y) np.fmin(x, y) | ndarry对位元素最小值的计算 |
| np.mod(x, y) | ndarry对位元素相除余数的计算, 即对位元素取模 |
| np.copysign(x, y) | 将ndarry y中各元素的符号赋给ndarry x中的对位元素 |
例如:
1 | import numpy as np |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 zzZ5的博客!
相关推荐


评论



