Python之Numpy库学习(3)
数据的CSV文件存取
CSV是英文Comma Separate Values(逗号分隔符)的缩写, 顾名思义, 文档的内容是由 “,” 分隔的一列列的数据构成的. CSV文档是一种编辑方便, 可视化效果极佳的数据存储方式. Python的Numpy库中有很多处理这种文档的方法.
存入CSV文件
存入CSV:
np.savetxt(frame, X, fmt=’%.18e’, delimiter=’ ‘, newline=’\n’, header=’’, footer=’’, comments=’#’ , encoding=None) [官方文档]
- frame: 文件, 字符串或产生器, 可以是.gz或.bz2的压缩文件
- X: 一维或二维ndarry数据, 将被存入文件中
- fmt: 写入文件的格式, 如%d, %.2f等
- delimiter: 用于列分割的字符串, 默认是空格
- newline: 用于行分割的字符串, 默认是换行
- header: 写在文件头部的字符串
- footer: 写在文件尾部的字符串
- comments: 注释
- encoding: 编码格式
例如:
1 | import numpy as np |
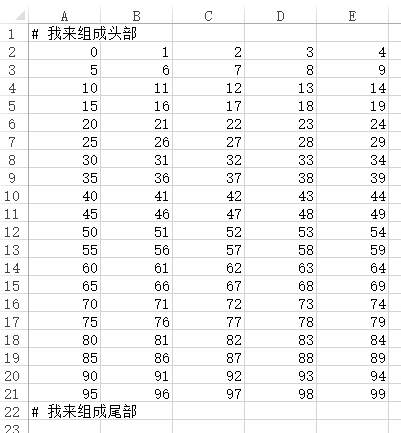
输出的文件为:
读取CSV文件
读取CSV:
numpy.loadtxt(fname, dtype=, comments=’#’, delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding=’bytes’, max_rows=None) [官方文档]
- frame: 文件, 字符串或产生器, 可以是.gz或.bz2的压缩文件
- dtype: 数据类型, 可选, 如 np.float, np.int32等
- comments: 注释
- delimiter: 用于列分割的字符串, 默认是空格
- converters: 根据字典将读取的数据自动转换
- skiprows: 跳过前几行, 包括注释, 默认为0
- usecols: 要读取的列数, 其中0为第一列. 例如, usecols=(1, 4, 5)将提取第2、第5和第6列. 默认None读取所有列
- unpack: 默认为False, 如果为True时读入属性将分别写入不同的数组变量
- ndmin: 返回的ndarry将至少具有ndmin维度. 否则, ndarry将被升维
- encoding: 编码格式, 默认为bytes
- max_row: 在skiprows后读取的行数, 默认Node是读取所有行
这里我们读取a.csv文件:
1 | import numpy as np |
注意:
csv只能用有效存储一维和二维数据, np.savetxt()和np.loadtxt()也只能有效存取一维和二维数组
多维数据的存取
存入多维数据
存入多维数据:
a.tofile(file, sep=””, format=”%s”) [官方文档]
- file: 文件, 字符串
- sep: 数据分割字符串,如果为空串, 写入文件为二进制
- format: 写入文件的格式
例如:
1 | import numpy as np |
读取多维数据
读取多维数据:
np.fromfile(file, dtype=float, count=-1, sep=””) [官方文档]
- file: 文件, 字符串
- dtype: 读取的数据类型
- count: 读入元素个数, 默认-1表示读入整个文件
- sep: 数据分割字符串,如果为空串, 读入文件为二进制
这里我们再用fromfile读取a.bat文件:
1 | import numpy as np |
注意:
该方法需要读取时知道存入文件时数组的维度和元素类型, 而且两个方法需要配合使用, 可以再增加一个文件存储数组维度和元素类型信息
当然也可以使用NumPy自带的.npy或压缩文件.npz来存储文件, 此时不需要数组维度和类型信息
NumPy的便捷文件存取
便捷存取数据:
numpy.save(file, arr, allow_pickle=True, fix_imports=True) [官方文档]
numpy.load(file, mmap_mode=None, allow_pickle=False, fix_imports=True, encoding=’ASCII’) [官方文档]
- file: 文件名, 以.npy为扩展名, 压缩扩展名为.npz
- arr: ndarry数组变量
- allow_pickle: 允许使用Python pickle保存对象数组. 不允许使用Pickle的原因包括安全性(加载Pickle数据可以执行任意代码)和可移植性(Pickle对象可能不能在不同的Python版本上加载). 默认为True
- fix_imports: 如果为True, Pickle将尝试将新的Python3名称映射到Python2中使用的旧模块名称, 以便Pickle数据流可以用Python2读取
- mmap_mode: (None, ‘r+’, ‘r’, ‘w+’, ‘c’), 如果不是None, 则使用给定模式对文件进行内存映射(有关模式的详细说明, 请参见numpy.memmap)
例如:
1 | import numpy as np |
NumPy的随机函数random库
np.random的随机数函数(1)
| 函数 | 说明 |
|---|---|
| np.random.rand(d0, d1, …, dn) | 根据d0-dn创建随机数数组, 浮点数, [0, 1), 均匀分布 |
| np.random.randn(d0, d1, …, dn) | 根据d0-dn创建随机数数组, 标准正态分布 |
| np.random.randint(low, high=None, size=None, dtype=’l’) | 根据size创建随机整数或整数数组, 范围是[low, high) |
| np.random.seed(seed=None) | 随机数种子, seed是给定的种子 |
例如:
1 | import numpy as np |
这是三种创建随机数组的方法, 事实上所有编程创建随机数的方法都是伪随机, 根据随机数种子生成的随机数, 相同的种子生成的随机数相同.
例如:
1 | np.random.seed(10) |
可以看到, 在随机数种子相同的情况下, 使用randint生成的ndarry完全相同.
np.random的随机数函数(2)
| 函数 | 说明 |
|---|---|
| np.random.shuffle(x) | 根据数组x的第1轴进行随机排列, 改变ndarry数组x |
| np.random.permutation(x) | 根据数组x的第1轴进行随机排列并生成一个新的数组, 不改变数组x |
| np.random.choice(a, size=None, replace=True, p=None) | 从一维数组a中以概率p抽取元素, 形成size形状的新数组, replace表示是否可以重用元素, 默认为True |
例如:
1 | import numpy as np |
通过例子可以看出, 乱序只是针对第一轴进行, 并不是完全乱序.而且shuffle会改变原数组, 而permutation并不会改变原数组.
1 | import numpy as np |
需要注意, a必须为一维数组, 而choice函数中的参数replace代表是否可以重用元素, 默认是可以.
np.random的随机数函数(3)
还有一些比较特殊的随机生成数组的函数
| 函数 | 说明 |
|---|---|
| np.random.uniform(low=0.0, high=1.0, size=None) | 根据size创建具有均匀分布的数组, 范围是[low, high) |
| np.random.normal(loc=0.0, scale=1.0, size=None) | 根据size创建具有正态分布的数组, loc为均值, scale为标准差 |
| np.random.poisson(lam=1.0, size=None) | 根据size创建具有泊松分布的数组, lam为随机事件发生率 |
例如:
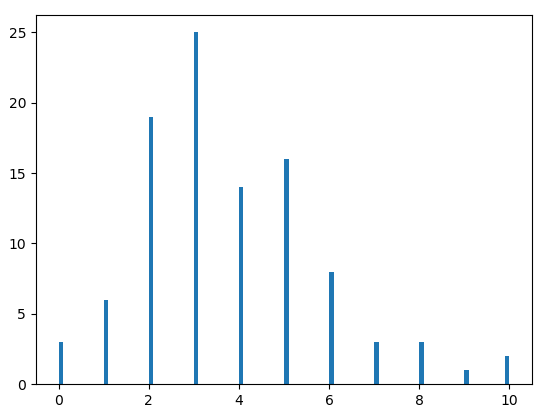
1 | import numpy as np |
均匀分布数组a的直方图:
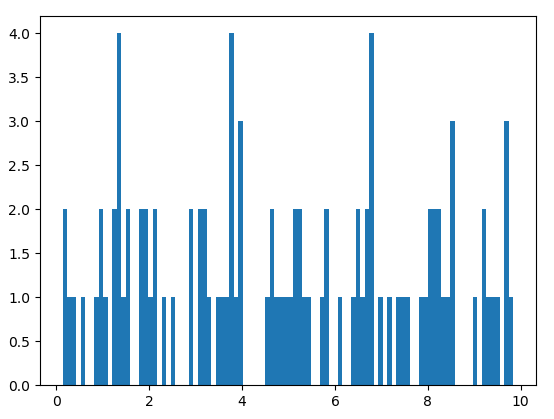
正态分布数组b的直方图:
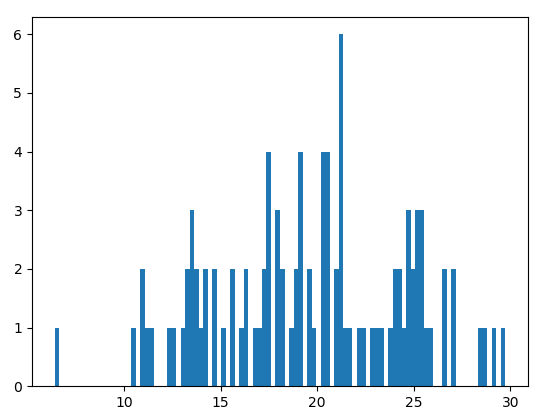
泊松分布数组c的直方图: