
Python之Requests库学习
Requests库简介
Requests 唯一的一个非转基因的 Python HTTP 库, 人类可以安全享用.Requests 允许你发送纯天然,植物饲养的 HTTP/1.1 请求, 无需手工劳动. 你不需要手动为 URL 添加查询字串, 也不需要对 POST 数据进行表单编码. Keep-alive 和 HTTP 连接池的功能是 100% 自动化的, 一切动力都来自于根植在 Requests 内部的 urllib3.
Requests库的安装
安装Requests库的最快也是最简单的方法是在shell上使用以下命令:pip install requests
一般使用时直接import即可import requests
Request库的get()方法
requests.get(url, **kwargs) 源代码
- url : 拟获取界面的url链接.
- **kwargs : 可选参数.
- 返回 response类
例如:
1 | import requests |
其中返回的Response对象的属性如下:
| 属性 | 描述 |
|---|---|
| r.status_code | HTTP请求的返回状态, 200表示连接成功, 404表示连接失败 |
| r.text | HTTP响应内容的字符串形式, 即, url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
| r.raise_for_status | 如果状态不是200, 引发HTTPError异常 |
一般流程如下:
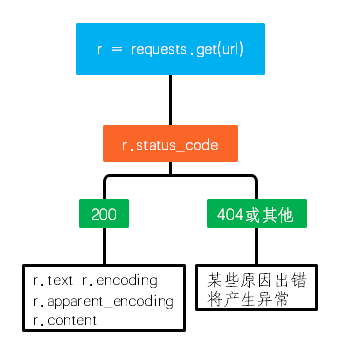
Requests库的异常处理
| 异常 | 描述 |
|---|---|
| requests.ConnectionError | 网络连接错误异常, 如DNS查询失败, 拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数, 产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时, 产生超时异常 |
Requests库方法
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应HTTP协议的GET |
| requests.head() | 获取HTML网页头信息的方法,对应HTTP协议的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应HTTP协议的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应HTTP协议的PUT |
| requests.patch() | 向HTML网页提交局部修改,对应HTTP协议的PATCH |
| requests.delete() | 向HTML网页提交删除请求的方法,对应HTTP协议的DELETE |
HTTP请求方法:
根据HTTP标准,HTTP请求可以使用多种请求方法。
| 方法 | 说明 |
|---|---|
| GET | 请求获取URL位置的资源 |
| HEAD | 请求获取URL位置资源的响应报告, 即获取该资源的头部信息 |
| POST | 请求向URL位置的资源后附加新的的数据 |
| PUT | 请求向URL位置储存一个资源, 覆盖原URL位置的资源 |
| PATCH | 请求局部更新URL位置的资源, 即改变该处资源的部分内容 |
| DELETE | 请求删除URL位置的资源, 即改变该处资源的部分内容 |
| CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器 |
| OPTIONS | 允许客户端查看服务器的性能 |
| TRACE | 回显服务器收到的请求, 主要用于测试或诊断 |
以图灵智能聊天机器人api为例:
1 | import requests |
输出结果:
1 | 发送请求 : {"reqType": 0, "perception": {"inputText": {"text": "\u4f60\u597d\u554a"}}, "userInfo": {"apiKey": "b3b72c45c1a342dc9e920e285edfd648", "userId": "zzZ5"}} |
再以获取b站用户信息为例:
1 | >>>import requests |
Requests库主要方法解析
requests.request(method, url, **kwargs) 源代码
- method : 请求方式, 对应’GET’/‘HEAD’/‘POST’/‘PUT’/‘PATCH’/‘delete’/‘OPTIONS’ 7种方式.
- url : 拟获取界面的url链接.
- **kwargs : 可选参数.
其中**kwargs :
- params : 字典或字节序列, 作为参数增加到url中.
如 :
1 | par = {'highlight': 'Request'} |
- data : 字典, 字节序列或文件对象, 作为Request的内容.
- json : JSON格式的数据, 作为Request的内容.
- headers : 字典, HTTP定制头.
- cookies : 字典或CookiesJar, Request中的cookie.
- auth : 元组, 支持HTTP认证功能.
- files : 字典类型, 传输文件.
- timeout : 设定超时时间, 秒为单位.
- proxie : 字典类型, 设定访问代理服务器, 可以增加登录认证.
- allow_redirects : True/False, 默认为True, 重新定向开关.
- stream : True/False, 默认为True, 获取内容立即下载开关.
- verify : True/False, 默认为True, 认证SSL证书开关.
- cert : 本地SSL证书路径.
例如: 百度/必应搜索关键词提交
百度搜索: https://www.baidu.com/s?wd=keyword
必应搜索: https://cn.bing.com/search?q=keyword
1 | import requests |
robots.txt文件
robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件, 它通常告诉网络搜索引擎的爬虫, 此网站中的哪些内容是不应被搜索引擎的爬虫获取的, 哪些是可以被爬虫获取的. 因为一些系统中的URL是大小写敏感的, 所以robots.txt的文件名应统一为小写. robots.txt应放置于网站的根目录下.
robots.txt协议并不是一个规范, 而只是约定俗成的, 所以并不能保证网站的隐私. 注意robots.txt是用字符串比较来确定是否获取URL,所以目录末尾有与没有斜杠”/“表示的是不同的URL. robots.txt允许使用类似”Disallow: *.gif”这样的通配符.
允许所有的爬虫:
1 | User-agent: * |
另一写法:
1 | User-agent: * |
仅允许特定的爬虫:(name_spider用真实名字代替):
1 | User-agent: name_spider |
拦截所有的爬虫:
1 | User-agent: * |
禁止所有爬虫访问特定目录:
1 | User-agent: * |
仅禁止坏爬虫访问特定目录(BadBot用真实的名字代替):
1 | User-agent: BadBot |
禁止所有爬虫访问特定文件类型:
1 | User-agent: * |





