
Python之Scrapy库学习
Scrapy库简介
Scrapy, Python开发的一个快速, 高层次的屏幕抓取和web抓取框架, 用于抓取web站点并从页面中提取结构化的数据. Scrapy用途广泛, 可以用于数据挖掘, 监测和自动化测试.
Scrapy吸引人的地方在于它是一个框架, 任何人都可以根据需求方便的修改. 它也提供了多种类型爬虫的基类, 如BaseSpider, sitemap爬虫等; 最新版本又提供了web2.0爬虫的支持.
Scrapy库的安装
安装Scrapy库的最快也是最简单的方法是在shell上使用以下命令:pip install scrapy
Scrapy爬虫框架解析
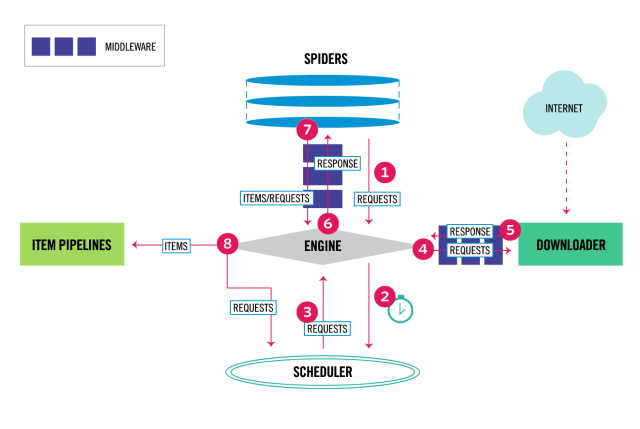
数据流的3个路径
- 一:
- Engine从Spider处获得爬取请求(Request)
- Engine将爬取请求转发给Scheduler, 用于调度
- 二:
- Engine从Scheduler处获得下一个要爬取的请求
- Engine将爬取请求通过中间件发送给Downloader
- 爬取网页后,Downloader形成响应(Response), 通过中间件发送给Engine
- Engine将收到的响应通过中间件发送给Spider处理
- 三:
- Spider处理响应后产生爬取项(scraped Item)和新的爬取请求(Requests)给Engine
- Engine将爬取项发送给Item PipeLine(框架出口)
- Engine将爬取请求发送给Scheduler
数据流的出入口
Engine控制各模块数据流, 不间断从Scheduler处获得爬取请求, 直至请求为空.
框架入口:Spider的初试爬取请求(Request)
框架出口:Item Pipeline
各个模块(5+2结构)
Engine(不需要用户修改)
- 控制所有模块之间的数据流
- 根据条件触发事件
Downloader(不需要用户修改)
根据请求下载网页
Scheduler(不需要用户修改)
对所有爬取请求进行调度管理
Downloader Middleware(用户可以编写配置代码)
- 目的: 实施Engine, Scheduler和Downloader之间进行用户可配置的控制
- 功能: 修改, 丢弃, 新增请求或响应
Spider(需要用户编写配置代码)
- 解析Downloader返回的响应(Response)
- 产生爬取项(scraped item)
- 产生额外的爬取请求(Request)
Item Pipelines(需要用户编写配置代码)
- 以流水线方式处理Spider产生的爬取项
- 由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型
- 可能操作包括:清理、检验和查重爬取项中的HTML数据,将数据存入数据库
Spider Middleware(用户可以编写配置代码)
- 目的:对请求和爬取项的再处理
- 功能:修改、丢弃、新增请求或爬取项
Scrapy爬虫的常用命令
Scrapy命令行:
Scrapy是为持续运行设计的专业爬虫框架, 提供操作的Scrapy命令行.
Scrapy命令行格式:>scrapy<command>[options][args]
Scrapy常用命令:
| 命令 | 描述 | 格式 |
|---|---|---|
| startproject | 创建一个新工程 | scrapy startproject<name>[dir] |
| genspider | 创建一个爬虫 | scrapy genspider[options]<name><domain> |
| settings | 获得爬虫配置信息 | scrapy setting[options] |
| crawl | 运行一个爬虫 | scrapy crawl<spider> |
| list | 列出工程中所有爬虫 | scrapy list |
| shell | 启动URL调试命令行 | scrapy shell[url] |
创建一个scrapy项目
在命令行界面可以使用 startproject 命令直接创建scrapy项目:
1 | C:\Users\zzZ5>d: |
此时scrapy自动在当前目录下创建一个新的爬虫工程项目.
生成的工程目录:
| 目录 | 描述 |
|---|---|
| zzZ5/ | 目录外层 |
| scrapy.cfg | 部署Scrapy爬虫的配置文件 |
| zzZ5/zzZ5/ | Scrapy框架的用户自定义Python代码 |
| __init__.py | 初始化脚本 |
| items.py | Items代码模板(继承类) |
| middlewares.py | Middlewares代码模板(继承类) |
| pipelines.py | Pipelines代码模板(继承类) |
| settings.py | Scrapy爬虫配置文件 |
| spiders/ | Spiders代码模板目录(继承类) |
| spiders/__init__.py | 初始文件, 无需修改 |
| spiders/__pycache__/ | 缓存目录, 无需修改 |
创建一个scrapy爬虫
在spiders目录下面, 我们可以使用命令行命令 scrapy genspider demo zzZ5.xyz 自动生成一个 demo.py 爬虫文件, 也可以在spiders目录下自己手动创建一个 demo.py 爬虫文件(爬虫名可以任意取). 爬虫文件的内容大致为以下这些:
1 | # -*- coding: utf-8 -*- |
接下来在工程目录下面, 使用命令行命令 scrapy crawl demo 即可运行该爬虫.
scrapy爬虫类型
Request类
类型为class scrapy.http.Request(), 表示一个HTTP请求, 由Spider生成, 由Downloader执行.
Request类的属性和方法:
| 属性/方法 | 描述 |
|---|---|
| .url | Request对应的请求URL地址 |
| .method | 对应的请求方法, ‘GET’, ‘POST’等 |
| .headers | 字典类型风格的请求头 |
| .body | 请求内容的主体, 字符串类型 |
| .meta | 用户添加的扩展信息, 在Scrapynei’bu模块间传递信息使用 |
| .copy() | 复制该请求 |
Response类
类型为class scrapy.http.Response(), 表示一个HTTP响应, 由Downloader生成, 由Spider处理.
Request类的属性和方法:
| 属性/方法 | 描述 |
|---|---|
| .url | Request对应的URL地址 |
| .status | HTTP状态码, 默认是200 |
| .headers | Response对应的头部信息 |
| .body | Response对应的内容信息, 字符串类型 |
| .flags | 一组标记 |
| .request | 产生Response类型的Request对象 |
| .copy() | 复制该响应 |
Item类
类型为class scrapy.item.Item(), 表示一个从HTML页面提取的信息内容, 由Spider生成, 由Item Pipeline处理.
Item类似字典类型, 可以按照字典类型操作.
Scrapy爬虫提取信息的方法
Scrapy爬虫支持多种HTML信息提取方法, 如: Beautiful Soup, lxml, re, XPath Selector, CSS selector等.
CSS selector的用法
我们要提取的就是zzZ5.xyz中的<title>zzZ5的个人博客</title>这个标签里面的数据, 我们最终要得到的是:”zzZ5的个人博客” 这么一段字符串.
那我们就循序渐进的看看我们会怎么操作, 会使用哪些函数.
首先我们需要在命令行输入:scrapy shell https://zzZ5.xyz
就这样一个格式, 其实这段代码就是一个下载的过程, 一执行这么一段代码scrapy就立马把我们相应链接的相应页面给拿到了,那接下来就可以任你处置了(差不多就是调试提取数据用的命令).
然后我们继续在命令行输入如下命令:response.css('title')
response.css(‘标签名’), 标签名的话可以是html标签比如: title, body, div, 也可以是你自定义的class标签.
那当我们输入以上命令之后, 你会发现已经提取了一些数据:
1 | >>> response.css('title') |
那你会发现,我们使用这个命令提取的一个Selector的列表, 并不是我们想要的数据; 那我们再使用scrapy给我们准备的一些函数来进一步提取, 改变一下上面的写法, 输入:
1 | >>> response.css('title').extract() |
我们只是在后面加入了: .extract() 这么一个函数你就提取到了我们标签的一个列表, 更近一步了, 那如果我们不要列表, 只要title这个标签, 要怎么处理呢? 看我们的输入:
1 | >>> response.css('title').extract()[0] |
这里的话, 我们只需要在后面添加: [0], 那代表提取这个列表中的第一个元素, 那就得到了我们的title字符串; 这里的话scrapy也给我提供了另外一个函数, 可以这样来写, 一样的效果:
1 | >>> response.css('title').extract_first() |
extract_first()就代表提取第一个元素, 和我们的: [0] 一样的效果, 只是更简洁些, 至此我们已经成功提取到了我们的title, 但是你会发现多了一个title标签, 这并不是你需要的, 那要怎么办呢, 我们可以继续改变一下以上的输入:
1 | >>> response.css('title::text').extract_first() |
我们在title后面加上了 ::text , 这代表提取标签里面的数据, 至此, 我们已经成功提取到了我们需要的数据:
‘zzZ5的个人博客’
总结一下, 其实就这么一段代码:response.css('title::text').extract_first()
配置pipelines.py
可以通过配置pipelines.py, 对获得的数据进行进一步的处理.
原文件为:
1 | # -*- coding: utf-8 -*- |
其中每个 item pipeline 都共会调用四个方法, 这里给出三个常用的方法:
process_item(self, item, spider):
每个pipeline都调用此方法. process_item()返回一个带有数据的dict或一个Item(或任何子类)对象.open_spider(self, spider)
当爬虫open的时候调用.close_spider(self, spider)
当爬虫close的时候调用
在 item pipeline 中编写完处理数据程序后, 在settings.py中的ITEM_PIPELINES中将该类添加进去.
配置settings.py
下面给出一些常用的设置:
| 选项 | 描述 |
|---|---|
| CONCURRENT_REQUESTS | Downloader最大并发请求下载数量, 默认32 |
| CONCURRENT_ITEMS | Item Pipeline最大并发ITEM处理数量, 默认100 |
| CONCURRENT_REQUESTS_PER_DOMAIN | 每个目标域名最大的并发请求数量, 默认8 |
| CONCURRENT_REQUESTS_PER_IP | 每个目标IP最大的并发请求数量, 默认为0, 非零有效 |





