
使用scikit-learn实现决策树
什么是决策树?
决策树(Decision Trees)一般都是自上而下的来生成的. 每个决策或事件(即自然状态)都可能引出两个或多个事件, 导致不同的结果, 把这种决策分支画成图形很像一棵树的枝干, 故称决策树.
决策树是一种用来分类和回归的无参监督学习方法, 其目的是创建一种模型从数据特征中学习简单的决策规则来预测一个目标变量的值.
决策树的优缺点
决策树的优点:
- 便于理解和解释, 树的结构可以可视化出来.
- 训练需要的数据少.
- 训练树模型的时间复杂度是$O(log_2n)$.
- 能够处理离散值也可以处理连续值.
- 能够处理多路输出的问题.
- 使用白盒模型.
- 可以通过数值统计测试来验证该模型.
- 即使该模型假设的结果与真实模型所提供的数据有些违反, 其表现依旧良好.
决策树的缺点:
- 决策树模型容易产生一个过于复杂的模型, 这样的模型对数据的泛化性能会很差, 即过拟合. 这个问题可以通过一些策略像剪枝, 设置叶节点所需的最小样本数或设置树的最大深度来避免.
- 决策树可能是不稳定的, 因为数据中的微小变化可能会导致完全不同的树生成. 这个问题可以通过决策树的集成来得到缓解.
- 在多方面性能最优和简单化概念的要求下, 学习一棵最优决策树通常是一个NP-Complete问题. 因此, 实际的决策树学习算法是基于启发式算法, 例如在每个节点进行局部最优决策的贪心算法. 这样的算法不能保证返回全局最优决策树. 这个问题可以通过集成学习来训练多棵决策树来缓解, 这多棵决策树一般通过对特征和样本有放回的随机采样来生成.
- 有些概念很难被决策树学习到, 因为决策树很难清楚的表述这些概念.
- 如果某些类在问题中占主导地位会使得创建的决策树有偏差. 因此, 建议在拟合前先对数据集进行平衡.
scikit-learn决策树算法类库简单介绍
scikit-learn决策树算法类库内部实现是使用了调优过的CART树算法, 既可以做分类, 又可以做回归. 分类决策树的类对应的是DecisionTreeClassifier, 而回归决策树的类对应的是DecisionTreeRegressor. 两者的参数定义几乎完全相同, 但是意义不全相同.
分类
简单分类
DecisionTreeClassifier 是能够在数据集上执行多分类的类, 与其他分类器一样, DecisionTreeClassifier 采用输入两个数组: 数组X, 用 [n_samples, n_features] size的数据来储存训练样本. 整数值数组Y, 用 [n_samples] 来保存训练样本的类标签.
下面简单展示一下如何按照给身高分类:
我们简单给出一组身高数据, 用0代表女性, 1代表男性, 分别用 0, 1指代低, 高两类身高(简单以165和175为一个界限, 不代表个人观点).
数据如下:
| 性别 | 身高 | 分类 | 性别 | 身高 | 分类 |
|---|---|---|---|---|---|
| 0 | 158 | 0 | 1 | 165 | 0 |
| 0 | 160 | 0 | 1 | 171 | 0 |
| 0 | 156 | 0 | 1 | 180 | 1 |
| 0 | 165 | 1 | 1 | 178 | 1 |
| 0 | 171 | 1 | 1 | 168 | 0 |
| 0 | 149 | 0 | 1 | 172 | 0 |
| 0 | 168 | 1 | 1 | 177 | 1 |
| 0 | 170 | 1 | 1 | 182 | 1 |
| 0 | 162 | 0 | 1 | 162 | 0 |
在建立决策树之前, 要先对数据进行预处理, 使X中的每一个特征都大概在一个数据范围
1 | X = [[0, 158], [0, 160], [0, 156], [0, 165], [0, 171], [0, 149], [0, 168], [0, 170], [0, 162], [1, 165], [1, 171], [1, 180], [1, 178], [1, 168], [1, 172], [1, 177], [1, 182], [1, 162]] |
可视化
我们可以使用 export_graphviz 导出器以 Graphviz 格式导出决策树, 关于 Graphviz 可以参见我的上一篇文章 使用Graphviz(dot命令)绘制流程图.
1 | dot_data = tree.export_graphviz(clf, out_file=None) |
此时我们就获得了该决策树的Graphviz图数据, 将其写入.gv或者.dot文件即可:
1 | with open("test.gv", 'w') as f: |
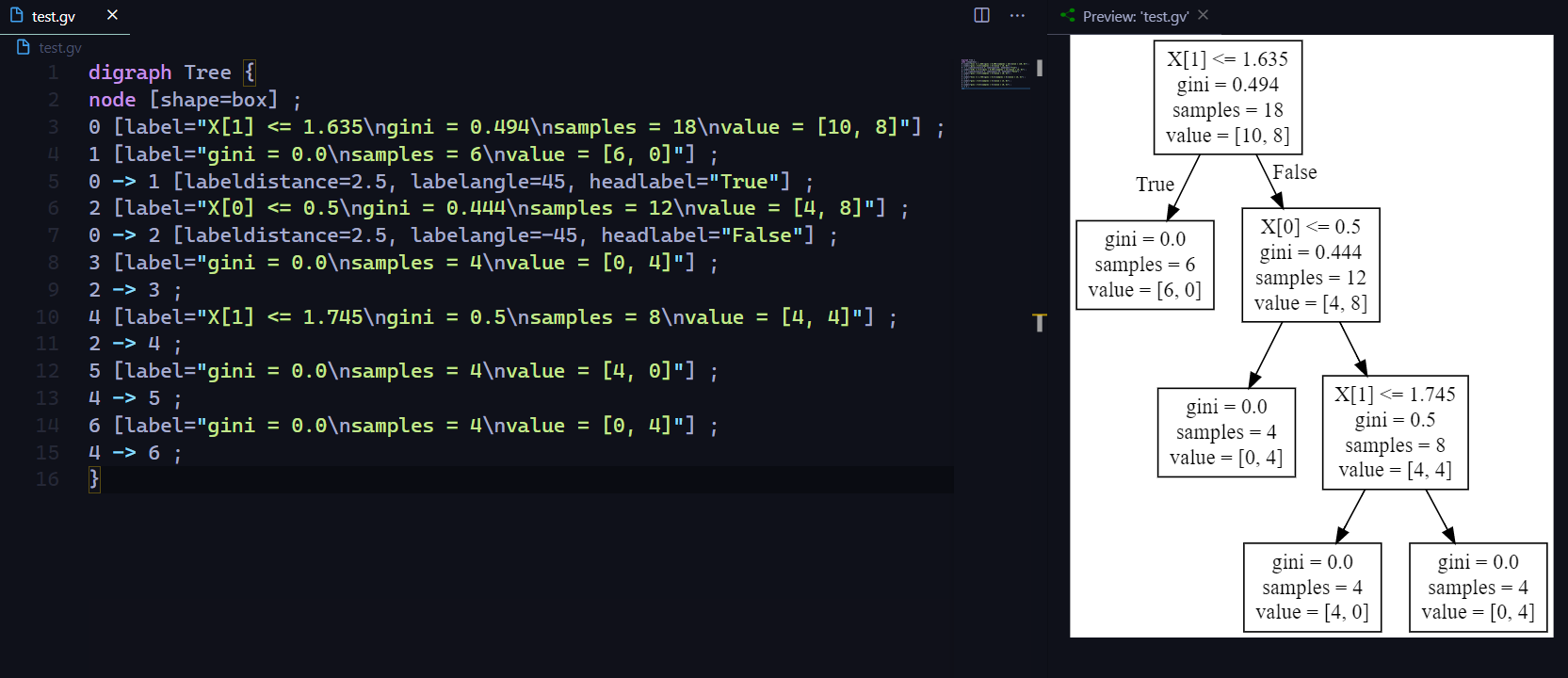
输出的Graphviz图像如下:

export_graphviz 还支持各种美化, 包括通过他们的类着色节点(或回归值), 如果需要, 还能使用显式变量和类名.
1 | dot_data = tree.export_graphviz(clf, out_file=None, |
输出的Graphviz图如下:

tips: 除了图像外, 还可以用
export_text导出器导出文字的描述, 可以自己尝试一下.
scikit-learn自带的鸢尾花数据
我们使用scikot-learn自带的鸢尾花(Lris)数据集, 可以构造一个决策树.
如下所示:
1 | from sklearn.datasets import load_iris |
可以使用同样的方法导出Graphviz图像:
1 | dot_data = tree.export_graphviz(clf, out_file=None, |
输出结果如图:

回归
决策树通过使用 DecisionTreeRegressor 类来解决回归问题.
实际用法和分类问题差不多, 但是需要注意的是输入的y值和输出的预测值都是float而非int.
一些需要注意的重要参数
大部分参数使用默认值即可, 但是有些参数在必要的时候还是需要更改:
| 参数 | 描述 |
|---|---|
| splitter(特征划分点选择标准) | 可以使用 “best” 或者”random”. 前者在特征的所有划分点中找出最优的划分点; 后者是随机的在部分划分点中找局部最优的划分点. 默认的”best”适合样本量不大的时候, 而如果样本数据量非常大, 此时决策树构建推荐”random” |
| max_features(划分时考虑的最大特征数) | 可以使用很多种类型的值, 默认是”None”, 意味着划分时考虑所有的特征数. 如果是”log2”意味着划分时最多考虑$log_2n$个特征; 如果是”sqrt”或者”auto”意味着划分时最多考虑$\sqrt{n}$个特征. 如果是整数, 代表考虑的特征绝对数. 如果是浮点数, 代表考虑特征百分比数的特征. 其中n为样本总特征数. 一般来说, 如果样本特征数不多, 比如小于50, 我们用默认的”None”就可以了; 如果特征数非常多, 我们可以灵活使用刚才描述的其他取值来控制划分时考虑的最大特征数, 以控制决策树的生成时间. |
| max_depth(决策树最大深度) | 决策树的最大深度, 默认可以不输入, 如果不输入的话, 决策树在建立子树的时候不会限制子树的深度. 一般来说,数据少或者特征少的时候可以不管这个值. 如果模型样本量多, 特征也多的情况下, 推荐限制这个最大深度, 具体的取值取决于数据的分布. 常用的可以取值10-100之间. |
| min_samples_split(内部节点再划分所需最小样本数) | 这个值限制了子树继续划分的条件, 如果某节点的样本数少于min_samples_split, 不会继续再尝试选择最优特征来进行划分. 默认是2. 如果样本量不大, 不需要管这个值. 如果样本量数量级非常大, 则推荐增大这个值. |
| min_samples_leaf(叶子节点最少样本数) | 这个值限制了叶子节点最少的样本数, 如果某叶子节点数目小于样本数, 则会和兄弟节点一起被剪枝. 默认是1, 可以输入最少的样本数的整数, 或者最少样本数占样本总数的百分比. 如果样本量不大, 不需要管这个值. 如果样本量数量级非常大,则推荐增大这个值. |
| max_leaf_nodes(最大叶子节点数) | 通过限制最大叶子节点数, 可以防止过拟合, 默认是”None”, 即不限制最大的叶子节点数. 如果加了限制, 算法会建立在最大叶子节点数内最优的决策树. 如果特征不多, 可以不考虑这个值, 但是如果特征分成多的话, 可以加以限制, 具体的值可以通过交叉验证得到. |
| class_weight(类别权重) | 指定样本各类别的的权重, 主要是为了防止训练集某些类别的样本过多, 导致训练的决策树过于偏向这些类别. 这里可以自己指定各个样本的权重, 或者用”balanced”, 如果使用“balanced”, 则算法会自己计算权重, 样本量少的类别所对应的样本权重会高. 当然, 如果你的样本类别分布没有明显的偏倚, 则可以不管这个参数, 选择默认的”None” |
实际使用技巧和注意事项
- 当样本少数量但是样本特征非常多的时候, 决策树很容易过拟合. 一般来说, 样本数比特征数多一些会比较容易建立健壮的模型.
- 如果样本数量少但是样本特征非常多, 在拟合决策树模型前, 推荐先做降维, 比如主成分分析(PCA), 线性判别分析(LDA), 特征选择(Losso)等. 这样特征的维度会大大减小, 再来拟合决策树模型效果会好.
- 使用
max_depth=3作为初始树深度, 先观察下生成的决策树里数据的初步拟合情况, 然后再决定是否要增加深度. - 通过使用
min_samples_split和min_samples_leaf来控制叶节点上的样本数量. 当这个值很小时意味着生成的决策树很可能会过拟合, 然而当这个值很大时将会不利于决策树的对样本的学习. 所以尝试min_samples_leaf=5作为初始值. 如果样本的变化量很大, 可以使用浮点数作为这两个参数中的百分比. - 在训练模型前, 注意观察样本的类别情况(主要指分类树), 如果类别分布非常不均匀, 就要考虑用class_weight来限制模型过于偏向样本多的类别.
- 所有的决策树内部使用 np.float32 数组, 如果训练数据不是这种格式, 将会复制数据集再进行运算.
参考文献
[1] 1.10. Decision Trees — scikit-learn 0.23.1 documentation
[2] 决策树 - MBA智库百科
[3] scikit-learn决策树算法类库使用小结 - 刘建平Pinard - 博客园






